Ticket #101 (closed defect: fixed)
27th June 2010 Site Downtime
| Reported by: | chris | Owned by: | chris |
|---|---|---|---|
| Priority: | critical | Milestone: | |
| Component: | Live server | Keywords: | |
| Cc: | ed, john, jim | Estimated Number of Hours: | 0.0 |
| Add Hours to Ticket: | 0 | Billable?: | yes |
| Total Hours: | 0.5 |
Description
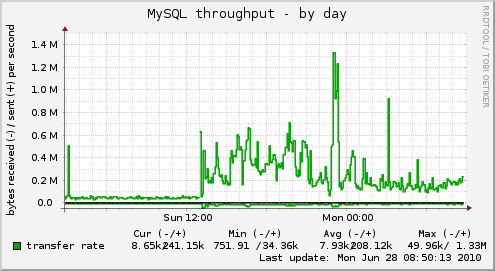
On Sunday 27th June the site was down for about 10 hours, see the attached graph of MySQL throughput.
Following are some extract from the emails sent from Gaia regarding this issue.
We need to investigate the cause of this to see if we can avoid it happening in the future...
The issue was the 'variable' table in the "live" drupal database had crashed. I took the web server fully offline for a few minutes just now as I repaired that table and then brought it back online.
The homepage is now working fine, but other pages are still generating errors.
There's a backup of the database I took just now at:
/web/transitionnetwork.org/live.20100627.sql
I had to take the site back down again and manually emptied all 'cache*' tables in the database.
we received emails into support@… from two people browsing the site early this morning. The default server error notice includes a reference to our support email.
So what can be done to mitigate this in the future:
You should review Drupal related logs to see if it gives any clues as to what caused the crash. An action on the 'variable' table in the database could be a clue, as that as the sole table crashed in the db.
There would have been a faster response to the outage on our side if our monitors had been specifically watching the drupal database named "live" as well as a more content specific monitor for an actual page generated by Drupal. We can coordinate on monitor customization, just let us know.
it looks like the internal server errors starting happening right after /cron.php was run at 23:00 UTC:
transitiontowns.gaiahost.coop - - [26/Jun/2010:23:00:00 +0000] "GET /cron.php HTTP/1.0" 200 - "-" "ApacheBench/2.3"
It specifically didn't look like a corruption related to a regular system or database backup process. The other traffic at this time was normal.
Attachments
{kind=link}
Change History
Changed 6 years ago by chris
- Attachment transitiontowns.gaiahost.coop-mysql_bytes-day.png added
comment:1 Changed 6 years ago by chris
- Add Hours to Ticket changed from 0.0 to 0.5
- Total Hours changed from 0.0 to 0.5
There are lots of errors in the logs during the downtime, the first error was triggered by the cron run at Sunday, 27 June 2010 - 12:00am:
Table 'variable' is marked as crashed and should be repaired query: UPDATE variable SET value = 'd:0.06666666666666666574148081281236954964697360992431640625;' WHERE name = 'node_cron_comments_scale' in /web/transitionnetwork.org/www/includes/bootstrap.inc on line 523.
https://www.transitionnetwork.org/admin/reports/event/174362
After 4 log entries like the above the errors changed to:
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ') ORDER BY fit DESC LIMIT 0, 1' at line 1 query: SELECT * FROM menu_router WHERE path IN () ORDER BY fit DESC LIMIT 0, 1 in /web/transitionnetwork.org/www/includes/menu.inc on line 315.
https://www.transitionnetwork.org/admin/reports/event/174367
And the above error then appears to have been repeated for every request to the site.
comment:2 Changed 6 years ago by jim
Interesting.... The variables table holds common variables that are used site-wide by Drupal - it shouldn't be super-heavily updated but some variables might get to be quite big strings of JSON.
All cache* tables are wipe-able, and indeed should be wiped after any major DB operation as a matter of course.
The log file errors are consistent with what you say Chris, and what I just said: variables table is requested in its entirety for each request, and often broken data will get into a cache table which just needs wiping or waiting for its next clearance.
Drupal (or indeed any application) using a DB table should not be able to corrupt it in normal use, unless that database has problems, bugs or issues with the underlying hardware...
My questions are:
- Is MySQL patched and up to date?
- Has this server's physical memory been tested recently? How about the disks?
- What do the MySQL and SysLog? logs show? Could /tmp or /var or /etc (or similar) have run out of disk space momentarily?
comment:3 Changed 6 years ago by john
This is a weird one. The previous cron ran without any problems and I re-created the crashed variable table using Chris's dump to see if anything looked amiss (I couldn't see anything). The problem occurred early on in the 12am cron run, the first 4 errors are from subsequent modules that are running their cron processes and realizing that the variable table is corrupt. As it's not happened before or since and I don't think there is anything special running on the cron at that time, we may not see it happening again. Agree though, would check that there is nothing wrong with the space allocation and possibly hardware (unlikely I know) and that there wan't a brief power outage at that time.
comment:4 Changed 6 years ago by chris
My questions are:
- Is MySQL patched and up to date?
The server is running:
Server version: 5.1.39-log FreeBSD port: mysql-server-5.1.39
5.1.48 is available: http://www.freebsd.org/cgi/cvsweb.cgi/ports/databases/mysql51-server/
- Has this server's physical memory been tested recently? How about the disks?
I don't know.
- What do the MySQL and SysLog?? logs show? Could /tmp or /var or /etc (or similar) have run out of disk space momentarily?
No shortage of disk space:
Filesystem Size Used Avail Capacity Mounted on /dev/mirror/gm0s1a 129G 19G 100G 16% /
I'll check the logs next...
comment:5 Changed 6 years ago by chris
MySQL is currently only set to log slow queries (in /var/db/mysql ), perhaps we should change this, and there is nothing in /var/log/messages
Should we consider if some automatic cleaning up of cache tables and checking of the variable table is needed, or should we just wait to see if this happens again and fix it when it does?
Perhaps we should wait to see if the problem happens again after the site has been migrated to the new hardware.
comment:6 Changed 6 years ago by jim
As long as errors are logged, that's fine - no point logging everything.
And I don't think the cache tables should be auto-cleared, there's no point unless a DB operation is done directly on the database, not through Drupal Drupal clears these tables when it needs to, and developers do whenever they've done something that needs it too. For normal sites running normally, clearing the caches just slows things down.
I definitely agree that, apart from MySQL error logging, waiting for new hardware is the best bet.
MySQL throughput